1.2 Funciones y características
1.3 Evolución histórica
1.4 Clasificación
1.5 Estructura (niveles o estratos de diseño)
1.6 Núcleo
1.6.1 Interrupciones (FLIH).
1.6.2 Despachador(Scheduler).
1.6.3 Primitivas de comunicación(IPC).
1.1 Definicion y Concepto
Colección de mecanismos de software destinados a servir de interface entre un sistema informático y sus usuarios, el cual ofrece herramientas y facilidades para simplificar las tareas de diseño, codificación, depuración, actualización, etc. Administra los recursos hardware y software que constituyen el sistema informático a explotar. Nació con la necesidad de llevar el control de quién utiliza los recursos software (usuario(s)). Componentes principales: manejo de procesos, entrada/salida, manejo de memoria y del sistema de archivos. Un sistema de computación consta de hardware, programas del sistema y programas de aplicación.

1.2 Funciones y características.
Las funciones básicas de un sistema operativo son:
- soporte para la ejecución de sw(software) de aplicación
- elemento de diagnóstico de hw(hardware)
- elemento de una red de computadoras
- elemento que optimiza el aprovechamiento de los recursos lógicos y físicos de un sistema de cómputo}
1.3 Evolución histórica.
Los primeros sistemas.
En un principio sólo existía el hardware de la computadora. Las primeras computadoras eran (físicamente) grandes máquinas que se operaban desde una consola. Una sola persona programaba y operaba el equipo.
Accesos por operador
En 1955 se separaron las funciones informáticas: Programación, operación y mantenimiento. El operador se encarga del manejo de la máquina (cargar programas, obtener resultados, hacer respaldos, etc.) y el programador dejó de tener acceso a la computadora.
Los programadores daban al operador los trabajos, éste los reunía y los ejecutaba uno tras otro y recogía los resultados entregándolos a los programadores.
Otra solución: El operador agrupaba los trabajos similares en requerimientos y los ejecutaba como si fueran un bloque (todos los de cobol, todos los de fortran), así se cargaba sólo una vez el compilador.
Secuencia automática de trabajos
El trabajo del operador era muy rutinario y podía automatizarse. Se diseñó un programa que transfería automáticamente el control de un trabajo a otro, el monitor residente (1er sistema operativo). Al encender el equipo el control se daba al programa monitor, este lo pasaba al 1er trabajo, el cual al terminar regresaba el control al monitor, y así sucesivamente. El monitor constaba de:

Mejora del rendimiento
Aun quedaba mucho tiempo del cpu ocioso debido a la diferencia de velocidad entre este y los dispositivos entrada/salida que eran mecánicos.
Off-Line
Aparecieron las cintas magnéticas, más rápidas que las tarjetas perforadas, pero secuenciales. Entonces se perforaban los programas en tarjetas y de ahí se pasaban a una cinta, esta cinta en bloque se pasaba a
drivers
secuenciador
Intérprete de tarjetas de control
Programa de usuario
Memoria
ejecución y los resultados en una nueva cinta y de ahí a la impresora. Las operaciones se hacían en dispositivos distintos lo que aumentaba la velocidad
On line
Lector de tarjetas->CPU->Impresora
Off Line
Lector de tarjetas->Unidad de Cinta->CPU->unidad de cinta->Impresora
Se podían tener varias lectoras de tarjetas y unidades de cinta y mantener ocupado al CPU, la desventaja era que el usuario debía esperar a que se llenara la cinta para ser atendido.
Buffering
Trata de mantener ocupados tanto el CPU como los dispositivos de E/S. Los datos se leen y se almacenan en un buffer (memoria intermedia), una vez que los datos se han leído y el CPU va a iniciar la operación, el dispositivo de entrada es instruido para iniciar inmediatamente la siguiente lectura. El CPU y el dispositivo de entrada permanecen ocupados. Cuando el CPU esté libre para el siguiente grupo de datos, el dispositivo de entrada habrá terminado de leerlos. El CPU podrá empezar el siguiente proceso y el dispositivo de entrada iniciará la lectura de los datos siguientes.
Para la salida, los resultados se descargan en otro buffer hasta que el dispositivo de salida pueda procesarlos.
Todo depende del tamaño del buffer y de la velocidad de procesamiento CPU y los E/S.
Spooling (SPOOL Simultaneous Peripheral Operation On Line)
El problema con los sistemas de cintas es que una lectora de tarjetas no podía escribir sobre un extremo de la cinta mientras el CPU leía el otro. Los sistemas de disco eliminaron esa dificultad, por su acceso directo. Las tarjetas se cargan directamente desde la lectora sobre el disco. Cuando se ejecuta un trabajo sus peticiones de entrada se satisfacen leyendo el disco. Cuando el trabajo solicita la salida, ésta se escribe en el disco. Cuando la tarea se ha completado se escribe en la salida realmente.
Se usa el disco como un buffer muy grande para leer por anticipado como sea posible de los dispositivos de entrada y para almacenar los archivos hasta que los dispositivos de salida sean capaces de aceptarlos.
La ventaja sobre el buffering es que el spooling traslapa la E/S de un trabajo con el procesamiento de otro.
Además mantiene una estructura de datos llama job spooling, que hace que los trabajos ya cargados permanezcan en el disco y el sistema operativo puede seleccionar cual ejecutar, por lo tanto se hace posible la planificación de trabajos mediante una cola por turno, tamaño o prioridad.
1.4 Clasificación.
Sistemas Operativos por Servicios
Esta clasificación es la más comúnmente usada y conocida desde el punto de vista del usuario final.
Monousuarios: un usuario a la vez, no importa el número de cpu’s, número de procesos que pueda ejecutar en un mismo instante de tiempo. PC’s.
Multiusuarios: más de un usuario a la vez, por varias terminales conectadas a la computadora o por sesiones remotas en una red de comunicaciones. No importa el número de cpu’s ni el número de procesos que cada usuario puede ejecutar simultáneamente.
Monotareas: sólo una tarea a la vez por usuario. Puede darse el caso de un sistema multiusuario y monotarea, varios usuarios al mismo tiempo pero cada uno de ellos puede estar haciendo solo una tarea a la vez.
Multitareas: realiza varias labores al mismo tiempo. interfases gráficas orientadas al uso lo cual permite un rápido intercambio entre las tareas para el usuario,
Monoprocesador: solamente un CPU, de manera que si la computadora tuviese más de uno le sería inútil. MS-DOS y MacOS.
1.5 Estructura (niveles o estratos de diseño).
Estructura monolítica.
Primeros sistemas operativos constituidos fundamentalmente por un sólo programa compuesto de un conjunto de rutinas entrelazadas de tal forma que cada una puede llamar a cualquier otra.
Características:
- Construcción del programa final a base de módulos compilados separadamente que se unen a través del encadenador (linker)
- Buena definición de parámetros de enlace entre las distintas rutinas existentes
- Carecen de protecciones y privilegios al entrar a rutinasque manejan diferentes aspectos de los recursos de la computadora
- Generalmente hechos a la medida, eficientes y rápidos en ejecución y gestión
- Poco flexibles para soportar diferentes ambientes de trabajo o aplicaciones.
Estructura jerárquica.
Mayores necesidades de los usuarios, mayor organización del software. Se dividió el sistema operativo en pequeñas partes, cada una bien definida y con una clara interfase con el resto de elementos.
Se constituyó una estructura jerárquica, el primero de los cuales fue denominado THE (Technische Hogeschool, Eindhoven)
Capa 5 – Control de programas de usuario
Capa 4 – Gestión de Archivos
Capa 3 – Control de operaciones entrada/salida
Capa 2 – Control de la Consola de operación
Capa 1 – Gestión de memoria
Capa 0 – Planificación de CPU
Otra forma es la de anillos.
Cada uno tiene una apertura por donde pueden entrar las llamadas de las capas inferiores. Las zonas más internas del sistema operativo o núcleo estarán más protegidas de accesos indeseados desde las capas más externas. Las internas serán más privilegiadas que las externas.
Cliente-servidor
El más reciente, puede ser ejecutado en la mayoría de las computadoras, para toda clase de aplicaciones, es de propósito general.
El núcleo establece la comunicación entre los clientes y los servidores. Los procesos pueden ser tanto servidores como clientes. Por ejemplo, un programa de aplicación normal es un cliente que llama al servidor correspondiente para acceder a un archivo o realizar una operación de entrada/salida sobre un dispositivo concreto. A su vez, un proceso cliente puede actuar como servidor para otro.

1.6 Núcleo.
El Núcleo.- Componente que interactúa directamente con el hardware. Contiene un conjunto de rutinas que hacen posible la ejecución de los programas y la comunicación entre ellos y el Hardware, es el que gestiona la entrada y salida del sistema, adaptándolas al hardware del sistema.

Núcleo (Kernel) y Niveles de un Sistema Operativo
Definición.
Es el software que constituye el núcleo del sistema operativo, dónde se realizan las funcionalidades básicas como la gestión de procesos, la gestión de memoria y de entrada salida.
El “kernel” del sistema operativo controla todas las operaciones que implican procesos y representa sólo una pequeña porción del código de todo el Sistema Operativo pero es de amplio uso.
Concepto de Kernel
Para que una computadora pueda arrancar y funcionar, no es necesario que tenga un núcleo para poder usarse. Los programas pueden cargarse y ejecutarse directamente en una computadora «vacía», siempre que sus autores quieran desarrollarlos sin usar ninguna abstracción del hardware ni ninguna ayuda del sistema operativo. Ésta era la forma normal de usar muchas de las primeras computadoras: para usar distintos programas se tenía que reiniciar y reconfigurar la computadora cada vez. Con el tiempo, se empezó a dejar en memoria (aún entre distintas ejecuciones) pequeños programas auxiliares, como el cargador y el depurador, o se cargaban desde memoria de sólo lectura. A medida que se fueron desarrollando, se convirtieron en los fundamentos de lo que llegarían a ser los primeros núcleos de sistema operativo.
El kernel presenta al usuario o los programas de aplicación una interfaz de programación de alto nivel, implementando la mayoría de las facilidades requeridas por éstos. Reúne el manejo de una serie de siguientes conceptos ligados al hardware de nivel más bajo:
- Procesos (tiempo compartido, espacios de direccionamiento protegidos);
- Señales y Semáforos;
- Memoria Virtual ("swapping", paginado);
- Sistema de Archivos; Tubos ("pipes") y Conexiones de red.
1.6.1 Interrupciones (FLIH).
La interrupción es el mecanismo mediante el cual otros módulos pueden interrumpir una secuencia normal de procesamiento. Ejemplos:
- Programa: división por cero
- Temporizador: cuando se cumple un tiempo específico
- E/S: cuando hay algo que comunicar
- Hardware: cuando ocurre una falla.
La gestión de interrupciones la realiza el manipulador (controlador) de interrupciones (FLIH, First Level Interrupt Handler) que es la parte del sistema operativo responsable de proporcionar la respuesta adecuada a las señales procedentes tanto del exterior como del interior del sistema (interrupciones externas e internas).
1.6.2 Despachador(Scheduler).
Se encarga de asignar los procesadores a los diferentes procesos, por lo tanto debe actuar cuando se debe comprobar si es necesario cambiar el proceso que está activo.
Esto involucra:
- cambio de contexto
- cambio a modo usuario
- salto a la dirección de memoria que corresponda al programa de usuario para continuar su ejecución.
Criterios de Despachador
- Utilización de CPU: mantener la CPU ocupada la mayor cantidad del tiempo posible
- Productividad (Throughput): # de procesos por unidad de tiempo
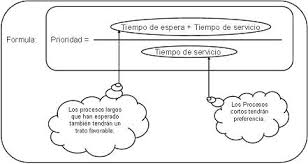
- Tiempo de servicio (Turnaround time): tiempo necesario para la ejecución de un proceso particular
- Tiempo de espera (Waiting time): tiempo total que el proceso se encuentra en la fila ready
- Tiempo de respuesta (Response time): tiempo que transcurre desde el requerimiento hasta que se produce la primera respuesta (en ambientes de tiempo compartido).
Criterios de Optimización
- Máxima utilización de CPU
- Máxima productividad
- Mínimo tiempo de servicio
- Mínimo tiempo de espera
- Mínimo tiempo de respuesta
1.6.3 Primitivas de comunicación (IPC).
Es una función básica de los Sistemas operativos. Los procesos pueden comunicarse entre sí a través de compartir espacios de memoria, ya sean variables compartidas o buffers, o a través de las herramientas provistas por las rutinas de IPC (Interprocess Communication).
La IPC provee un mecanismo que permite a los procesos comunicarse y sincronizarse entre sí. Normalmente a través de un sistema de bajo nivel de paso de mensajes que ofrece la red subyacente. La comunicación se establece siguiendo una serie de reglas (protocolos de comunicación).